Abstract
Electronics without silicon is unbelievable, but it will come true with the evolution of Diamond or Carbon chip. Now a day we are using silicon for the manufacturing of Electronic Chip's.It has many disadvantages when it is used in power electronic applications, such as bulk in size, slow operating speed etc. Carbon, Silicon and Germanium are belonging to the same group in the periodic table.
They have four valance electrons in their outer shell. Pure Silicon and Germanium are semiconductors in normal temperature. So in the earlier days they are used widely for the manufacturing of electronic components. But later it is found that Germanium has many disadvantages compared to silicon, such as large reverse current, less stability towards temperature etc so in the industry focused in developing electronic components using silicon wafers
Now research people found that Carbon is more advantages than Silicon. By using carbon as the manufacturing material, we can achieve smaller, faster and stronger chips. They are succeeded in making smaller prototypes of Carbon chip. They invented a major component using carbon that is "CARBON NANOTUBE", which is widely used in most modern microprocessors and it will be a major component in the Diamond chip.
WHAT IS IT?
 In single definition, Diamond Chip or carbon Chip is an electronic chip manufactured on a Diamond structural Carbon wafer. OR it can be also defined as the electronic component manufactured using carbon as the wafer. The major component using carbon is (cnt) Carbon Nanotube. Carbon Nanotube is a nano dimensional made by using carbon. It has many unique properties.
In single definition, Diamond Chip or carbon Chip is an electronic chip manufactured on a Diamond structural Carbon wafer. OR it can be also defined as the electronic component manufactured using carbon as the wafer. The major component using carbon is (cnt) Carbon Nanotube. Carbon Nanotube is a nano dimensional made by using carbon. It has many unique properties.
HOW IS IT POSSIBLE?
Pure Diamond structural carbon is non-conducting in nature. In order to make it conducting we have to perform doping process. We are using Boron as the p-type doping Agent and the Nitrogen as the n-type doping agent. The doping process is similar to that in the case of Silicon chip manufacturing. But this process will take more time compared with that of silicon because it is very difficult to diffuse through strongly bonded diamond structure. CNT (Carbon Nanotube) is already a semi conductor.
ADVANTAGES OF DIAMOND CHIP
1 SMALLER COMPONENTS ARE POSSIBLE
As the size of the carbon atom is small compared with that of silicon atom, it is possible to etch very smaller lines through diamond structural carbon. We can realize a transistor whose size is one in hundredth of silicon transistor.
2 IT WORKS AT HIGHER TEMPERATURE
Diamond is very strongly bonded material. It can withstand higher temperatures compared with that of silicon. At very high temperature, crystal structure of the silicon will collapse. But diamond chip can function well in these elevated temperatures. Diamond is very good conductor of heat. So if there is any heat dissipation inside the chip, heat will very quickly transferred to the heat sink or other cooling mechanics.
3 FASTER THAN SILICON CHIP
Carbon chip works faster than silicon chip. Mobility of the electrons inside the doped diamond structural carbon is higher than that of in he silicon structure. As the size of the silicon is higher than that of carbon, the chance of collision of electrons with larger silicon atoms increases. But the carbon atom size is small, so the chance of collision decreases. So the mobility of the charge carriers is higher in doped diamond structural carbon compared with that of silicon.
4 LARGER POWER HANDLING CAPACITY
For power electronics application silicon is used, but it has many disadvantages such as bulk in size, slow operating speed, less efficiency, lower band gap etc at very high voltages silicon structure will collapse. Diamond has a strongly bonded crystal structure. So carbon chip can work under high power environment. It is assumed that a carbon transistor will deliver one watt of power at rate of 100 GHZ. Now days in all power electronic circuits, we are using certain circuits like relays, or MOSFET inter connection circuits (inverter circuits) for the purpose of interconnecting a low power control circuit with a high power circuit .If we are using carbon chip this inter phase is not needed. We can connect high power circuit direct to the diamond chip
NEW TECH: (CONSTRUCTIVE DESTRUCTION) BY IBM:
Constructive destruction is new technique invented by IBM. It not a manufacturing method of carbon nanotube; but it is manipulated method. By the three methods mentioned above, we are getting both singled walled carbon nanotube and multi walled carbon nanotubes. All electronic applications require semi conducting carbon nanotubes. This method to separate semi conducting carbon nanotubes from metallic carbon nanotubes. It follows below step –
1. Deposit stick together carbon nanotubes on silicon dioxide water.
2. Use photographic methods to make electrodes on both ends of the carbon nanotube.
3. Make a gate electrode on the silicon dioxide water.
4. Using silicon dioxide water it self as the electrode, the scientist’s switched off. The semi conducting nanotubes by applying appropriate voltage to the silicon dioxide water. Which blocks any current flow through the semi conducting nanotube.
5. The metallic carbon nanotubes are unprotected, and appropriate carbon voltage is applied to destroy the metallic carbon nanotubes.
6. Result:- a dense array of un- harmed semi conducting carbon nanotubes are formed, which can be used for transistor manufacturing.
Atomic Force Microscope (AFM)
 "Atomic force microscopy (AFM) is a method of measuring surface topography on a scale from angstroms to 100 microns. The technique involves imaging a sample through the use of probe or tip, with a radius of 20nm. The tip is held several nanometers above the surface using a feedback mechanism that measures surface-tip interaction on the scale of nano Newton’s. Variation in tip height are recorded while the tip is scanned repeatedly"
"Atomic force microscopy (AFM) is a method of measuring surface topography on a scale from angstroms to 100 microns. The technique involves imaging a sample through the use of probe or tip, with a radius of 20nm. The tip is held several nanometers above the surface using a feedback mechanism that measures surface-tip interaction on the scale of nano Newton’s. Variation in tip height are recorded while the tip is scanned repeatedly"
Across the sample, producing a topographic image of the surface. In addition to basic AFM, the instrument in the Microscopy Suite is capable of producing images in a number of other modes, including tapping, magnetic force, and pulsed force. In tapping mode, the tip is oscillated above the sample surface, and data may be collected from interactions with surface topography, stiffness, and adhesion.
This result in an expanded number of image contrast methods compared to basic AFM. Magnetic force mode imaging utilizing a magnetic tip to enable the visualization of magnetic domains on the sample. In electrical force mode imaging a charged tip is used to locate and record variations in surface charge. In pulsed force mode (Witec), the sample is oscillated beneath the tip, and a serious of pseudo force – distance curves are generated. This permits the separation of sample topography, stiffness, and adhesion values, producing three independent images. Or three individual sets of data , Simultaneously

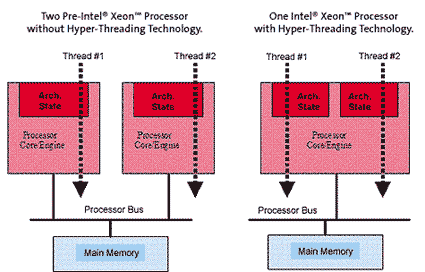 The first implementation of Hyper-Threading Technology is being made available on the Intel. Xeon processor family for dual and multiprocessor servers, with two logical processors per physical processor. By more efficiently using existing processor resources, the Intel Xeon processor family can significantly improve performance at virtually the same system cost. This implementation of Hyper-Threading Technology added less than 5% to the relative chip size and maximum power requirements, but can provide performance benefits much greater than that.
The first implementation of Hyper-Threading Technology is being made available on the Intel. Xeon processor family for dual and multiprocessor servers, with two logical processors per physical processor. By more efficiently using existing processor resources, the Intel Xeon processor family can significantly improve performance at virtually the same system cost. This implementation of Hyper-Threading Technology added less than 5% to the relative chip size and maximum power requirements, but can provide performance benefits much greater than that.


























{kind=link}